The Future of the Core TV Currency — The Big TV Screen

In 1968, C.E. Hooper (inventors of the Nielsen meter who licensed it to Nielsen in 1935 for $1,000,000) did a study in New York using a 10,000 home coincidental. Back then, the telephone coincidental was considered the standard of truth for TV measurements. There were no answering machines, far fewer dual earners, and different attitudes toward research. It was a proven assumption that the likelihood was 99% that no one was watching TV in a home if that home did not answer the phone within six rings. Therefore “No Answer” was counted as an answer (“TV off”). For these reasons, the response rate to coincidentals was 90%. There could be no memory error because what was asked was the TV viewing situation at the instant the phone rang seconds ago. The whole interview took only about a minute, less if the TV was off. There were some second sets and those were also measured. The legitimacy of NTI itself rested on validation against the telephone coincidental. The coincidental was The Truth Standard because of its least Nonresponse Error and least Response Error.
 At the end of this telephone coincidental, however, another question was asked: Would you be part of our panel? All we need to do is a quick hookup of a silent meter to your TV set — your identity will always be protected and we will pay you a thousand times more than the extra electricity cost.
At the end of this telephone coincidental, however, another question was asked: Would you be part of our panel? All we need to do is a quick hookup of a silent meter to your TV set — your identity will always be protected and we will pay you a thousand times more than the extra electricity cost.
About half of those in the coincidental audience agreed. They were then called back and told that the study was called off. This of course was because that study was simply a ruse to discern which homes would normally not be measured by meter panel. The coincidental — remember it was the most accurate method at the time, more accurate than any of today’s methods, because of people’s better attitude toward research — found stark differences by station in terms of the group that said it would take the meter versus the group that said no. One station enjoyed 40% inflated ratings as a result. Some stations were helped and others hurt if you based decisions on just the part of the sample that would have taken a set tuning meter.
Evidence and judgment both suggest it is time to start thinking again about the core of the TV currency, and how we can make it better.
Following are details of how the coincidental meter agreer ratings compared with the two actual meter panels in the market at the time, along with the key results of the New York Coincidental Study into set tuning meter Nonresponse.
Here are the key results:
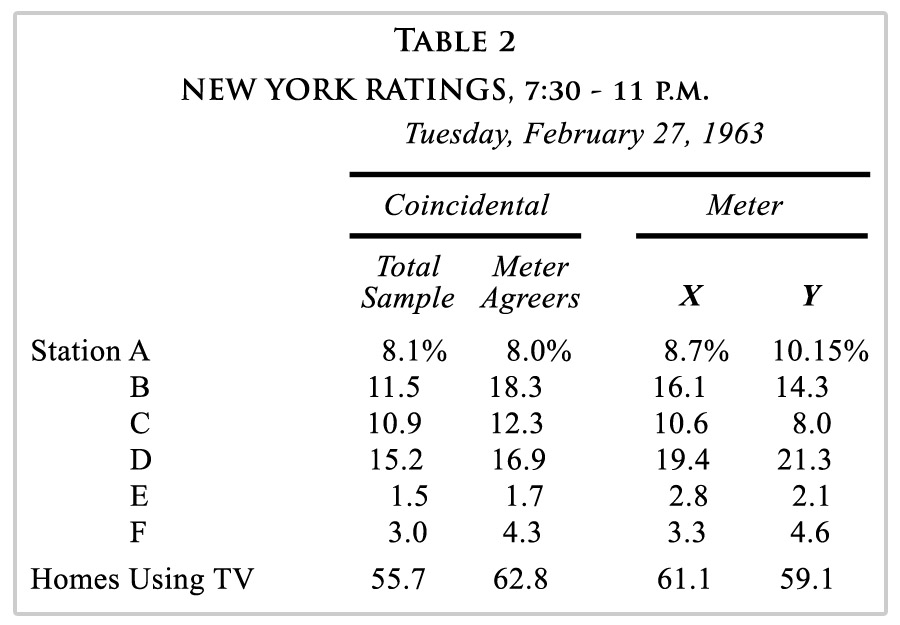
As you can see, Station B benefits greatly from the set tuning meter Nonresponse Bias. Among the total coincidental sample its prime time rating was 11.5 (ah, the good old days). But among the part of the coincidental sample that would have accepted a set tuning meter, it went up to 18.3.
Does this mean that a real set tuning meter panel would also inflate Station B? You betcha. Look at the last two columns. There were two set tuning meter panels in New York in those days, and both of them provided inflated ratings for Station B, one of them 26% above the truth standard total sample coincidental, the other meter panel a whopping 40% inflated over the truth standard.
This was about five years after CONTAM found about a 10% overall inflation in NTI (using the coincidental as its truth standard). This time the inflation was the 62.8 HUT shown in the table above for the Meter Agreers, over the 55.7 shown for the total coincidental sample — now 12.7% overall inflation five years later. Possibly a trend? If so, extending that 27% increase over five years to today would forecast an inflation rate I don’t even want to think about.
Talking to classical media researchers around the market there is suspicion that in fact all of the media measurements are slightly inflated, but that they are probably all increased by about the same percentage so we can ignore it. It would be nice to schedule some date in the future by when we want to actually know the facts of the case.
CRE has been active in doing Nonresponse studies that for some reason so far have not shown results as frightening as the Hooper results. Perhaps CRE would care to provide some data tables we could include and analyze in a future post. Maybe the explanation is that the national panel of 18,000 today is so much better than the small NY panels of 300 each at the time of the Hooper study.
Millions of dollars are at stake. “Millions” is small change on the scale of the discussion. For a small network, millions might be involved plus or minus in getting a currency that is more accurate in its reflection of what is going on with the big TV screens in the home. For a large network group, billions might be involved.
A more accurate TV currency might lower the in-home component — the largest component — of the ratings. Some would say this disadvantages television because ratings for the other media — even the small TV screen mobile measures — are all inflated, so they will get higher allocation than they deserve, and in-home TV will get less than it deserves.
Others like me might argue that audience size is becoming less important than ROI, and that ROI will drive allocation by media type, not audience size. Plus, everyone benefits from the greatest accuracy. More dollars flow to the medium whose metrics inspire more confidence. And in an ROI-based business such as this is fast becoming, the seller and agency will increasingly have aligned interests with the buyer, as the advertiser moves toward performance-based payments.
In the earlier era, the buyer side had the preponderance of brainiac media researchers. There are never more than a hundred such people in the business at any one time. When they were on the buyer side they pushed for quality to a degree that is now a distant memory.
Today the push for quality has no bite in it. Empty words because the business people on all sides do not see its importance and are busy making money for today, for this quarter’s head-patting/bonuses or flogging/firing. And most of the brainiac media researchers are now on the seller side, where in today’s environment their inherent and never-ending push for quality must be exercised with the greatest care and delicacy.
Education is clearly the answer. It’s time for the media research rock stars (I am already tired of “brainiacs”) to create their own or combined initiatives within or across their organizations, providing painless education as to the monetary benefits that will derive from improving the quality of the base measurement. ROI studies are not costly but they are costly enough so that they are under-used while ratings are voluminously always available. Therefore the ratings must be proven to be as accurate as available with all of today’s technologies.
Bill Harvey is a well-known media researcher and inventor who co-founded TRA, Inc. and is its Strategic Advisor. His nonprofit Human Effectiveness Institute runs his weekly blog on consciousness optimization. Bill can be contacted at bill@billharveyconsulting.com
Read all Bill’s MediaBizBloggers commentaries at In Terms of ROI.
Check us out on Facebook at MediaBizBloggers.com
Follow our Twitter updates @MediaBizBlogger
The opinions and points of view expressed in this commentary are exclusively the views of the author and do not necessarily represent the views of MediaBizBloggers.com management or associated bloggers. MediaBizBloggers is an open thought leadership platform and readers may share their comments and opinions in response to all commentaries.
[Image courtesy of Ambro/FreeDigitalPhotos.net]

Bill Harvey
Bill Harvey, who won an Emmy® Award in 2022 for his invention of set top box data, has spent over 35 years leading the way in media research with pioneer thinking in New Media, set top box data, optimizers, measurement standards, privacy standards, the A…