Artie Bulgrin conceived and led Project Blueprint, which showed how a probability sample could be used to calibrate and de-bias digital big data. In 2019 the World Federation of Advertisers (WFA) and the Association of National Advertisers (ANA) unveiled a blueprint for future cross-media measurement broadly based on the same ideas. With one exception. Whereas Project Blueprint found that duplication among media are definitely not random, the WFA/ANA blueprint allows for a concept of Virtual IDs which will tend to produce results that are very similar to random probability.
This is a very major disconnect between Project Blueprint and the Northstar initiative, as the WFA effort has been called. All of the hard work that has gone into the WFA project -- including APIs called HALO which help measurement companies create cross-media data based on Virtual People -- is undermined by this flaw at the core of everything.
For, if Virtual IDs are allowed in to the currency for cross-media, everyone can save a ton of money and effort and simply write a small Python script using the 1960s equation known as the Sainsbury formula (random probability) that can be used to simulate cross-media audience data, quite inaccurately. But if that is what the advertisers really want, it’s their money.
In other words, if random duplication is an acceptable assumption in making media buys aggregately in the hundreds of billions of dollars annually, we have all the tools we need. No one needs to build ambitious new systems like Nielsen ONE. Simply use the currency for the medium and determine reach within each medium, then combine those using random probability.
However, random duplication is not an acceptable assumption. Paul Donato, Chief Research Officer of the objective, scientific Advertising Research Foundation (ARF) and former Chief Research Officer of Nielsen, says, "The one thing we do truly know is that duplication is not random."
I’m about to show you, in this post, compelling proof that random duplication estimates can be very far from the truth. In fact, even hallucinating ChatGPT and other Large Language Models tell the truth more often than random duplication does.
Despite the WFA Northstar specs having given a hall pass, Nielsen went the other way and in Nielsen ONE uses random probability less than one percent of the time, as a last resort. And more than 99% of Nielsen ONE Ads is based on empirically measured duplication.
In doing this, Nielsen explicitly follows the line of thought development which runs through all of CONTAM, BARB, ARF, MRC and CIMM work since the 1960s Harris Committee Hearings, including Artie Bulgrin’s Project Blueprint.
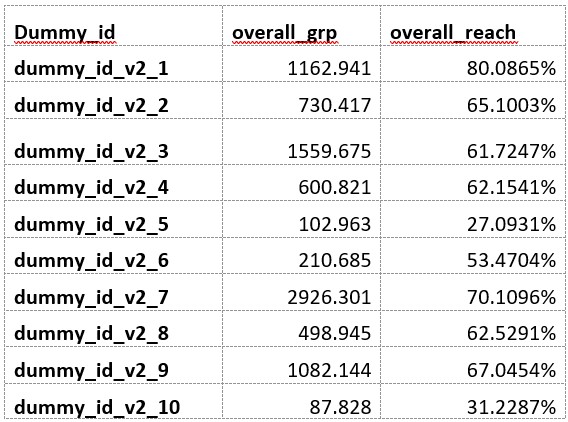
At my request, Nielsen’s Remy Spoentgen provided me with pair duplication data on a random sample of ten campaigns with the specs I had laid out:
- A range in GRP levels
- Use linear TV, CTV, computer and mobile media
Remy also applied the Sainsbury formula to estimate by the assumption of random duplication how those same pair duplications would have come out if Nielsen hadn’t done the hard work to get the most rigorous empirical duplications.
Here are the ten anonymized campaigns. Nielsen of course cannot reveal to us the brands involved.
First let’s look at the errors of random duplication when considering the campaign’s duplication between its linear TV and its CTV. The first column is the official Nielsen ONE Ads published numbers, the second column is what random probability would estimate that duplication to be, and the third column is the percent error in the random probability deviation from the empirical measurement number:
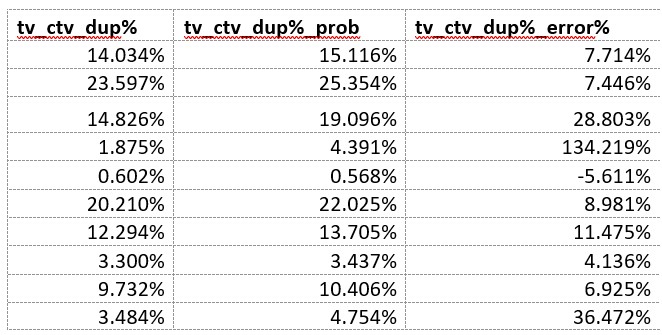
The errors do not follow any pattern I can discern that would enable adjustment factors to be of practical value. This is a case of where empirical measurement is not a "nice to have." Rather, it is a "must have."
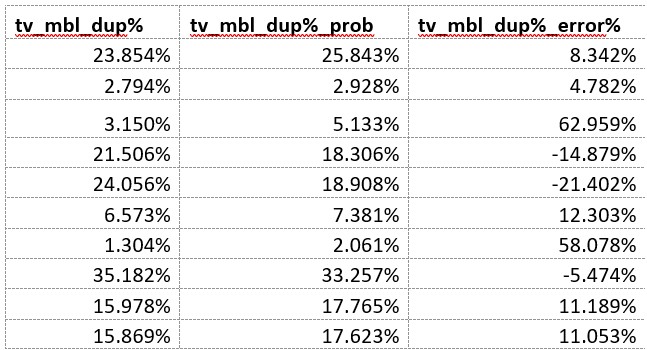
Here are the data for the TV-mobile duplications:
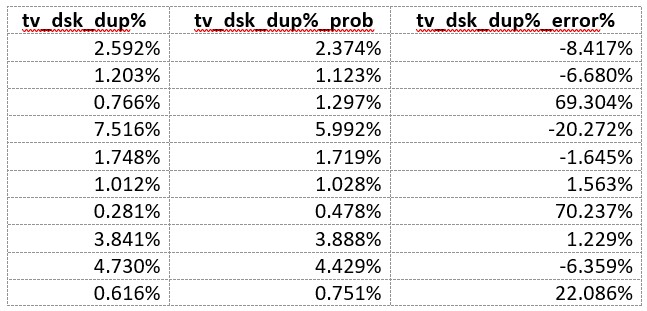
TV-computer:
CTV-Mobile:
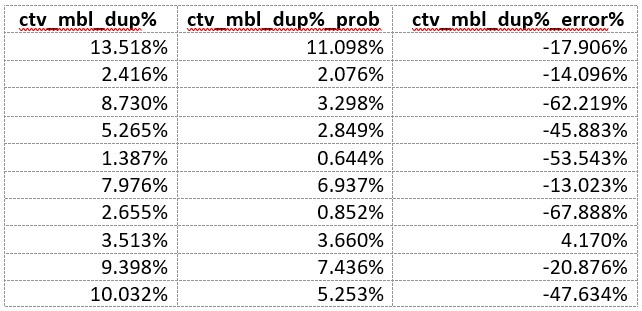
CTV-computer:
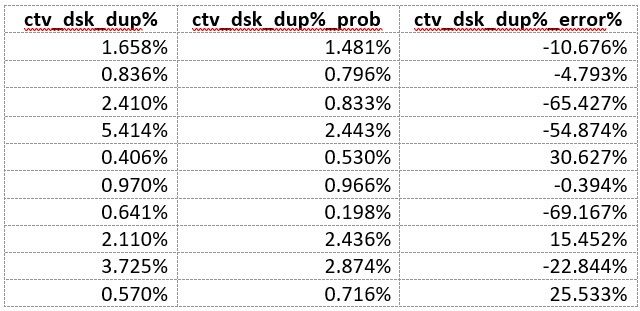
Between computer and mobile:
What if in the third campaign you were buying mobile and computer and got the signal that the overlap was enormous. You might drop one or the other. But that would be a mistake because the duplication was less than 4% of what it was said to be by a probability algorithm.
Either we need accurate data on the total population or we don’t. Until today, everything I’ve learned in the industry says that we must have the most complete, accurate and precise data possible, properly reflecting the total population, as long as the cost is kept down at a couple of percentage points of our top line, which is where research and data have always been. But a slight increase could be extremely smart, if invested correctly.
If we are going to talk the talk, we better walk the walk. I observe that CPM is still the decider, not ROI. I see that people do what’s easy and what they’ve always done and that tends to waste vast amounts of advertiser money.
The ANA just came out with a study that says advertisers wasted at least $20 billion last year in just programmatic digital alone.
We have all the tools we need to stop throwing money around and to place bets as scientifically as can be achieved today, but we must not cut corners in the quality of the data we send into those tools, or it’s all wasted.
The HALO tools should be used for planning estimates, not for post-evaluation nor outcome measurement. Privacy rules will not impede these things, as there are first-party data and legal platforms which cannot be turned off. HALO usage as planning tools alone more than justifies all the work that went into HALO. But we highly recommend against using Virtual IDs in activation, optimization, ROI, AI deep-learning models or post-evaluation. The data-driven decisions needed in those areas is at a much higher level of sensitivity to crude data. As the numbers above prove.
Last suggestion: Create a HALO 2.0 that uses empirical data, no VIDs.
Posted at MediaVillage through the Thought Leadership self-publishing platform.
Click the social buttons to share this story with colleagues and friends.
The opinions expressed here are the author's views and do not necessarily represent the views of